
Neural Networks Demystified: The Ultimate Guide for Young Tech Professionals
1. Introduction to Neural Networks
Neural networks are computational models inspired by the human brain. They consist of interconnected nodes (neurons) that process information and learn from data. Here’s what we’ll cover:
What are neural networks? Understand the basics and their significance.
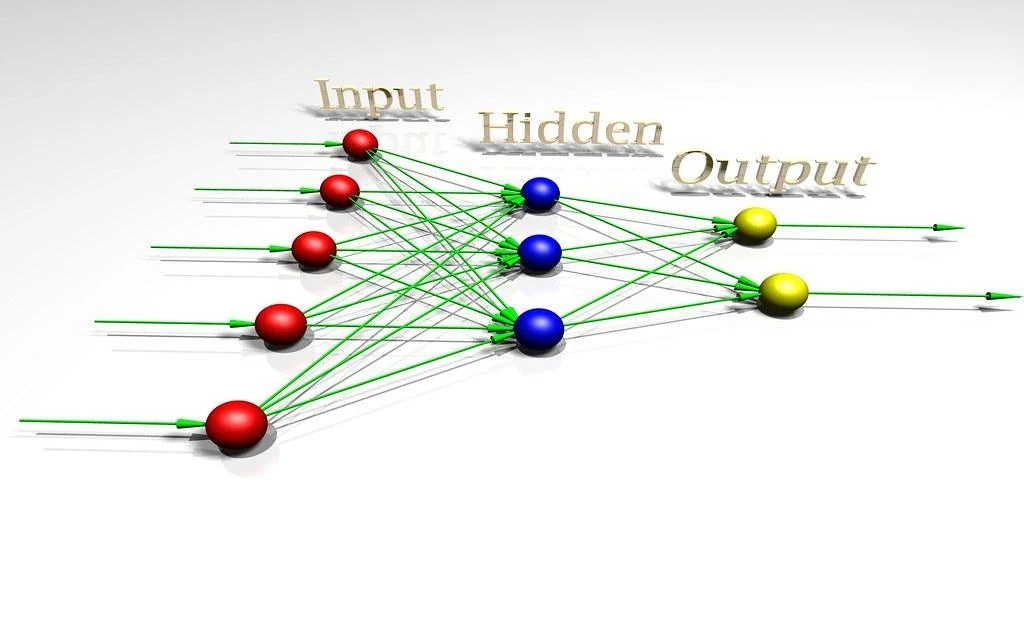
Neural networks are computational models inspired by the human brain's structure and function, designed to recognize patterns, make decisions, and solve problems by learning from data. At their core, neural networks consist of neurons organized into layers: an input layer that receives data, hidden layers that process data, and an output layer that produces the final result. Neurons in one layer are connected to those in the next via weighted connections, which are adjusted during training to minimize prediction errors. Activation functions are applied to introduce non-linearity, enabling the network to learn complex patterns. Training involves forward propagation, where data flows through the network to generate an output, and backward propagation, where errors are calculated and weights are updated to improve accuracy.
The significance of neural networks lies in their ability to recognize patterns, adapt to new data, and solve complex problems that traditional algorithms struggle with. They enhance automation and efficiency, driving innovations in various fields. Applications of neural networks include computer vision for facial recognition and medical imaging, natural language processing for chatbots and translation, speech recognition for voice assistants, recommendation systems for personalized suggestions, and autonomous vehicles for navigation and decision-making. As a cornerstone of artificial intelligence, neural networks enable the processing of vast data and intelligent decision-making, transforming technology and society.
Brief history and evolution: Explore their journey from early perceptrons to deep learning architectures.
The evolution of neural networks began with the perceptron in the 1950s, a simple model limited to binary classification. In the 1980s, multilayer perceptrons and the backpropagation algorithm enabled learning of non-linear functions. The 2000s saw the rise of deep learning, with convolutional neural networks (CNNs) revolutionizing image recognition. The 2010s introduced advanced architectures like AlexNet, RNNs, LSTMs, and GANs, leading to breakthroughs in various domains. Today, models like BERT and GPT, leveraging attention mechanisms and transformer architectures, are at the forefront of natural language processing, continuing to expand the capabilities of neural networks.
Why neural networks matter: Discover their impact in today’s tech landscape.
Neural networks are pivotal in today's tech landscape, driving advancements in AI across various fields. They excel at recognizing patterns and learning from vast datasets, powering applications like image and speech recognition, natural language processing, and autonomous systems. Neural networks enable innovations such as personalized recommendations, intelligent virtual assistants, and advanced medical diagnostics. Their ability to solve complex problems and improve over time makes them essential for automation, efficiency, and creating intelligent technologies, significantly transforming industries like healthcare, finance, and transportation. Their continuous evolution promises to further revolutionize how we interact with technology.
2. The Building Blocks of Neural Networks
Let’s dive into the essential components:

Neurons: The fundamental units that process input data and produce output. Layers (input, hidden, and output) connect these neurons.
Neurons are the fundamental units of neural networks, analogous to biological neurons in the human brain. Each neuron receives inputs, processes them, and generates an output. Inputs to a neuron are typically weighted sums of outputs from the previous layer's neurons. This weighted sum is then passed through an activation function, which introduces non-linearity and determines the neuron's output. The neuron's output is subsequently fed as input to neurons in the next layer.
Activation functions: Explore ReLU, sigmoid, and tanh functions and their roles.
Activation functions play a crucial role in neural networks by introducing non-linearity, which allows the network to model complex patterns in data. Three commonly used activation functions are ReLU, sigmoid, and tanh. ReLU (Rectified Linear Unit) outputs the input directly if it is positive, otherwise, it outputs zero, helping to mitigate the vanishing gradient problem and enabling faster, more efficient training of deep networks. The sigmoid function maps input values to a range between 0 and 1, making it useful for binary classification tasks, although it can suffer from the vanishing gradient problem, slowing down training. The tanh function maps input values to a range between -1 and 1, providing zero-centered outputs that can help with training convergence, despite also being prone to the vanishing gradient issue. Each of these activation functions has its specific applications and impacts the neural network's performance and efficiency.
3. Training Neural Networks
Master the art of training neural networks:
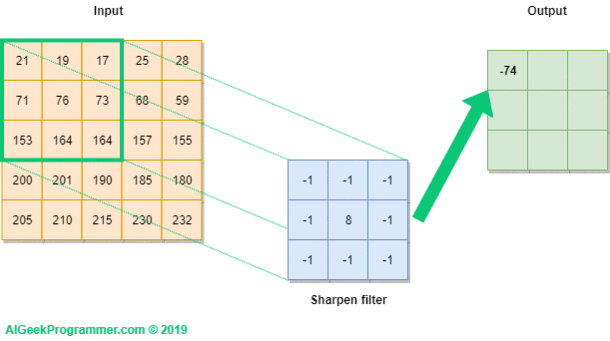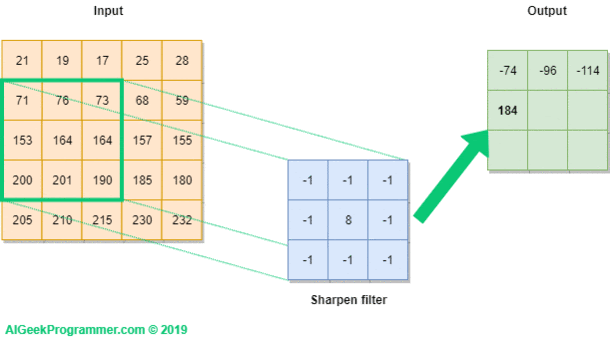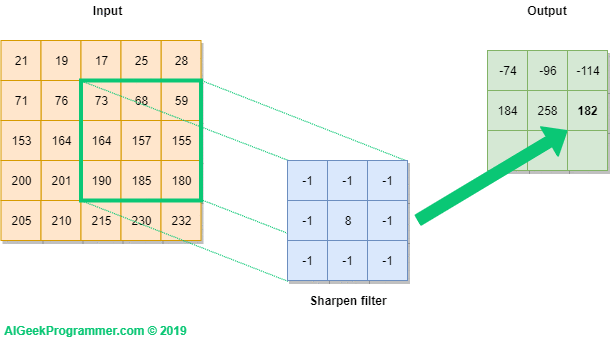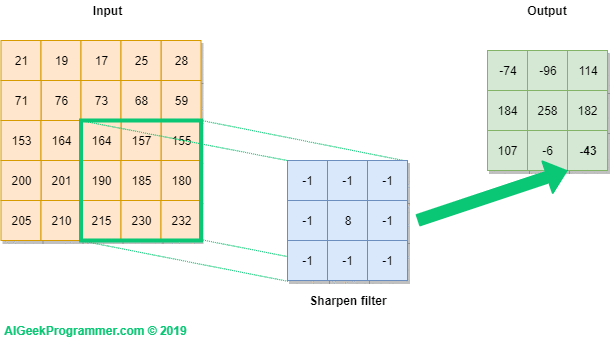
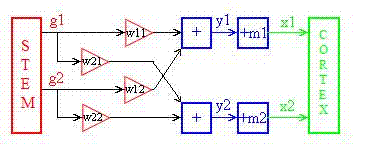
Backpropagation: Understand how weights are adjusted to minimize prediction errors.
Backpropagation is a fundamental algorithm used in training neural networks, crucial for minimizing prediction errors. It works by computing the gradient of the loss function with respect to each weight by the chain rule, effectively propagating the error backwards through the network. This process involves two main phases: forward propagation, where the input data passes through the network to generate predictions, and backward propagation, where the difference between predicted and actual values (the error) is calculated and used to update the weights. The weights are adjusted iteratively using gradient descent or other optimization algorithms to minimize the loss function, thereby improving the network's accuracy.
Loss functions and optimization algorithms: Learn the tools that guide the learning process.
Loss functions and optimization algorithms are essential in training neural networks, guiding the learning process to improve model accuracy. The loss function, or cost function, measures the difference between the network's predicted outputs and the actual targets. Common loss functions include mean squared error (MSE) for regression tasks, which calculates the average squared difference between predicted and true values, and cross-entropy loss for classification tasks, which quantifies the difference between the predicted class probabilities and the actual class labels. Optimization algorithms use the gradients of the loss function to adjust the network's weights and minimize the loss. Gradient descent, including its variants like stochastic gradient descent (SGD) and Adam, are popular optimization algorithms. Gradient descent updates weights iteratively based on the computed gradients to reduce the loss function, improving the model’s performance. Each optimization algorithm has its advantages: SGD offers simplicity and is suitable for large datasets, while Adam adapts learning rates based on past gradients, often leading to faster convergence. The choice of loss function and optimization algorithm significantly affects the training efficiency and effectiveness of the neural network.
Overfitting and underfitting: Strike the right balance for generalization.
Overfitting and underfitting are crucial issues in training neural networks that affect a model’s generalization ability. Overfitting occurs when a model learns the training data too well, capturing noise and resulting in high accuracy on training data but poor performance on new data. Underfitting happens when a model is too simple to learn the underlying patterns, leading to poor performance on both training and test data. Balancing these issues involves using techniques like cross-validation, regularization (e.g., L1, L2), dropout, and early stopping to ensure the model is appropriately complex, improving its ability to generalize to unseen data.
3. Tools and Frameworks for Neural Network Development.
Get hands-on with these tools:
TensorFlow and Keras: Popular libraries for building and training neural networks.

TensorFlow and Keras are essential libraries for neural network development. TensorFlow, developed by Google, offers a comprehensive framework for various machine learning tasks, while Keras, now part of TensorFlow, provides a user-friendly API for rapid prototyping and model building. Together, they facilitate efficient and scalable model creation.
PyTorch: Widely used for research and development.
PyTorch is a widely used open-source library for deep learning, favored for its flexibility and dynamic computation graph. Developed by Facebook, it facilitates rapid prototyping and experimentation, making it ideal for research and development. PyTorch’s user-friendly interface and efficient tensor operations support advanced model experimentation and development.
Cloud-based solutions: Google Cloud AI, AWS SageMaker, and more.
Cloud-based solutions like Google Cloud AI and AWS SageMaker provide scalable platforms for developing and deploying machine learning models. Google Cloud AI offers tools for various AI tasks, while AWS SageMaker streamlines the machine learning workflow from model building to deployment. Both solutions ensure efficient, scalable, and accessible machine learning development.
7. Future Trends and Career Opportunities
To stay ahead in the evolving field of neural networks, it's important to focus on several key areas. Emerging architectures such as transformers and attention mechanisms are revolutionizing AI, especially in natural language processing and computer vision, so keeping up with these innovations is crucial. **Ethical considerations** are equally important; addressing issues like bias, fairness, and transparency ensures responsible AI development and fosters trust in technology. For career positioning, continually learning and practicing are essential. Engaging with the neural network community through projects, conferences, and collaborations will not only keep you updated but also enhance your contributions to the field of artificial intelligence.
Thank you for reading!
We hope this information has provided valuable.
If you have any questions or would like to delve deeper into any topic, feel free to reach out. Your engagement and curiosity drive the advancement of technology and knowledge. Stay tuned for more updates and discussions on the latest developments in artificial intelligence and machine learning.
Break your limits and grow Skills! 🚀🤖
Post a Comment